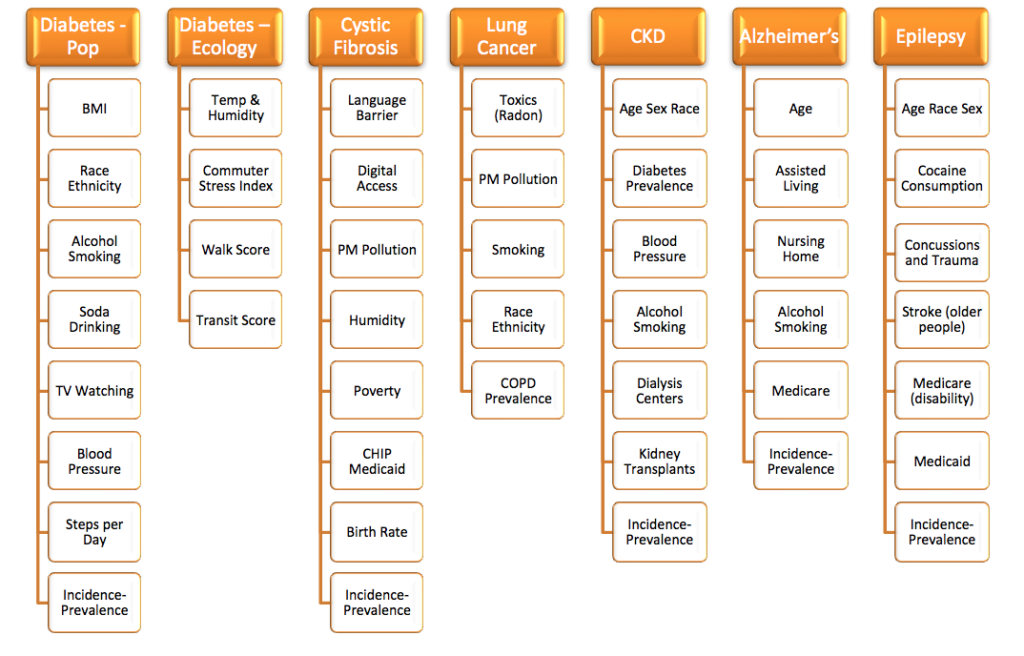
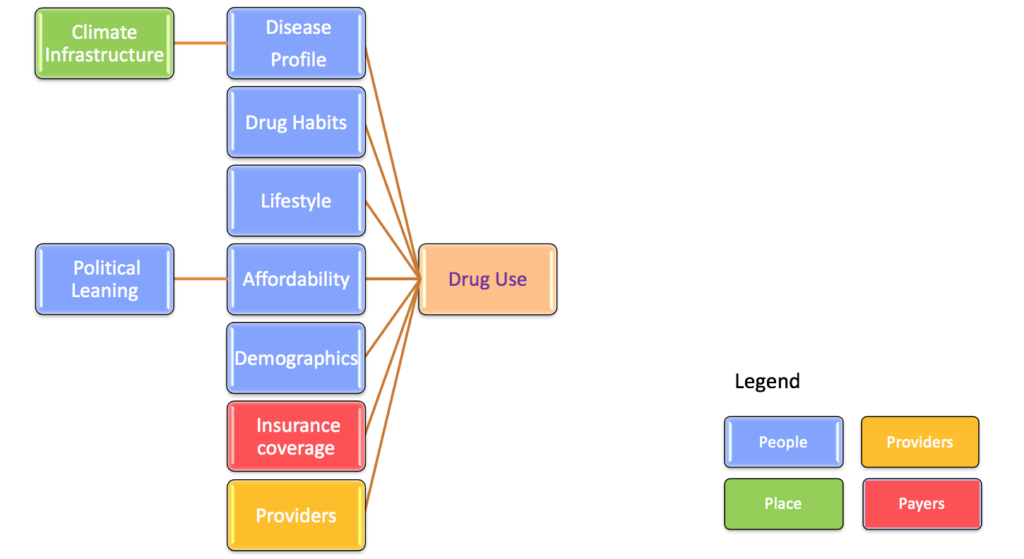
We wish to establish if there is a casual relationship between some property of a geography, say, high temperature and humidity and, say, the onset of diabetes. This is the kind of connections this database makes possible. What’s more, it has what’s needed to run propensity models.